What follows is a mostly complete description of the practical steps required for performing a short molecular dynamics simulation of a DNA duplex. Please do keep in mind the difference between doing things, and understanding things.
- Create a clean directory and cd in it.
- Get the CHARMM force field parameter and topology files :
- cp /usr/local/charmm27/par_all27_prot_na.inp ./
- cp /usr/local/charmm27/top_all27_prot_na.inp ./
- Download the coordinates for Dickerson's dodecamer from PDB [1] and save it on your disk.
- Edit the file ddoc.pdb and remove all lines that do not start with ATOM or TER. Also, retain the final END. Save the modified file which should look like this :
ATOM 5 O5* C A 1 18.935 34.195 25.617 1.00 64.35 1BNA 67
ATOM 6 C5* C A 1 19.130 33.921 24.219 1.00 44.69 1BNA 68
ATOM 7 C4* C A 1 19.961 32.668 24.100 1.00 31.28 1BNA 69
ATOM 8 O4* C A 1 19.360 31.583 24.852 1.00 37.45 1BNA 70
......
ATOM 493 N2 G B 12 19.208 25.386 26.096 1.00 29.76 1BNA 551
ATOM 494 N3 G B 12 18.350 23.438 27.053 1.00 21.95 1BNA 552
ATOM 495 C4 G B 12 17.231 22.893 27.570 1.00 13.89 1BNA 553
TER 496 G B 12 1BNA 554
END 1BNA 700
- rasmol ddoc.pdb to look at it.
- Now it is time to align the axes of inertia of the molecule with the orthogonal frame : prepare a file with the name moleman.csh containing the following :
#!/bin/tcsh -f
#
# This will read a PDB file and rotate/translate it so that
# 1. the centre of gravity will be at the origin
# 2. the axes of inertia will be aligned with the orthogonal frame
#
lx_moleman2 >& moleman.log << eof
/usr/local/xutil/moleman2.lib
REad ddoc.pdb
XYz ALign_inertia_axes
WRite aligned.pdb
quit
eof
exit
- Run it : source moleman.csh. This should create two files : a log file (moleman.log) and the new pdb (aligned.pdb).
- rasmol aligned.pdb and then set axes on (to confirm the changes).
- We need to prepare two pdb files each containing the coordinates of each of the two chains. The simplest approach is :
- Edit A.pdb and retain only the A-chain coordinates. Add an END at the end of the file. Repeat for B.pdb. For example, A.pdb should look like this :
ATOM 5 O5* C A 1 -18.727 -10.552 3.524 1.00 64.35 1BNA 67
ATOM 6 C5* C A 1 -17.323 -10.651 3.227 1.00 44.69 1BNA 68
ATOM 7 C4* C A 1 -17.096 -10.088 1.846 1.00 31.28 1BNA 69
.........
ATOM 245 N2 G A 12 18.548 0.358 -2.572 1.00 40.53 1BNA 307
ATOM 246 N3 G A 12 18.570 -1.926 -2.048 1.00 37.34 1BNA 308
ATOM 247 C4 G A 12 18.657 -2.793 -1.013 1.00 31.14 1BNA 309
END
- Create a file with the name psfgen.csh containing the following (see the NAMD manual for psfgen documentaion. For more details on using psfgen with DNA see [2]) :
#!/bin/tcsh -f
/usr/local/NAMD_2.5/psfgen >& psfgen.log << END
topology top_all27_prot_na.inp
alias residue C CYT
alias residue T THY
alias residue A ADE
alias residue G GUA
alias atom THY O5* O5'
alias atom THY C5* C5'
alias atom THY C4* C4'
alias atom THY O4* O4'
alias atom THY C1* C1'
alias atom THY C2* C2'
alias atom THY C3* C3'
alias atom THY O3* O3'
alias atom GUA O5* O5'
alias atom GUA C5* C5'
alias atom GUA C4* C4'
alias atom GUA O4* O4'
alias atom GUA C1* C1'
alias atom GUA C2* C2'
alias atom GUA C3* C3'
alias atom GUA O3* O3'
alias atom ADE O5* O5'
alias atom ADE C5* C5'
alias atom ADE C4* C4'
alias atom ADE O4* O4'
alias atom ADE C1* C1'
alias atom ADE C2* C2'
alias atom ADE C3* C3'
alias atom ADE O3* O3'
alias atom CYT O5* O5'
alias atom CYT C5* C5'
alias atom CYT C4* C4'
alias atom CYT O4* O4'
alias atom CYT C1* C1'
alias atom CYT C2* C2'
alias atom CYT C3* C3'
alias atom CYT O3* O3'
segment A {
first 5TER
last 3TER
pdb A.pdb
}
patch DEO2 A:2
patch DEO2 A:4
patch DEO2 A:5
patch DEO2 A:6
patch DEO2 A:10
patch DEO2 A:12
patch DEO1 A:1
patch DEO1 A:3
patch DEO1 A:7
patch DEO1 A:8
patch DEO1 A:9
patch DEO1 A:11
coordpdb A.pdb A
segment B {
first 5TER
last 3TER
pdb B.pdb
}
patch DEO2 B:2
patch DEO2 B:4
patch DEO2 B:5
patch DEO2 B:6
patch DEO2 B:10
patch DEO2 B:12
patch DEO1 B:1
patch DEO1 B:3
patch DEO1 B:7
patch DEO1 B:8
patch DEO1 B:9
patch DEO1 B:11
coordpdb B.pdb B
guesscoord
writepsf psfgen.psf
writepdb psfgen.pdb
END
exit
- Use it to generate a new pdb file (psfgen.pdb) and the PSF file (psfgen.psf) needed for the steps that follow : source psfgen.csh. Examine the output from the program (file psfgen.log).
- We now need to neutralise the DNA charges. The simple-minded approach (with VMD's autoionize plugin) used for proteins is not satisfactory for DNA : the ions' placement must take into account the DNA's electrostatic field. The best approach would have been to solve the Poisson-Boltzmann equation (with the program Delphi for example) and use the calculated field to guide ion placement. A more simple minded (and less computationally intensive) approach is to start placing the ions one-by-one using a simple Coulomb-based potential. This is implemented with the program sodium, do a less /usr/local/doc/sodium.c to read its documentation. The steps we need to take are :
- Prepare a PDB file containing partial charges on the B-factor column. This you do with a script this time for xplor. Save the following script in a file named xplor.sh, and run it with source xplor.sh.
#!/bin/tcsh -f
xplorbig > xplor.log << eof
structure @psfgen.psf end
coor @psfgen.pdb
vector do (B=CHARGE) (all)
write coor output="psfgen_charges.pdb" end
stop
eof
exit
- Examine the output (file psfgen_charges.pdb) and confirm that the charges are there.
- Prepare a configuration file for sodium with the name sodium.config containing the following :
NUM_IONS 22
R_ION_PRODNA 6.5
R_ION_ION 11.0
GRID_STEP 0.50
BORDER_WIDTH 10.0
PDB_NAME psfgen_charges.pdb
PDB_OUT ions.pdb
- Run it sodium < sodium.config > sodium.log. For such a small system it will only take a minute or two.
- Check the sodium.log file, check the ion distribution : cat psfgen.pdb ions.pdb > sodium_test.pdb ; rasmol sodium_test.pdb and then select not DNA, cpk.
- You can experiment by changing the sodium parameters controling either the minimum distance between ions and DNA, or the minimum ion-ion distance. Compare the resulting structures to see how the ions structure changes. How would you choose values for these two parameters ?
- Re-create PDB and PSF files for the system this time including the ions. To do this prepare a file psfgen_ions.sh containing the following :
#!/bin/tcsh -f
/usr/local/NAMD_2.5/psfgen >& psfgen_ions.log << END
topology top_all27_prot_na.inp
alias residue C CYT
alias residue T THY
alias residue A ADE
alias residue G GUA
alias atom THY O5* O5'
alias atom THY C5* C5'
alias atom THY C4* C4'
alias atom THY O4* O4'
alias atom THY C1* C1'
alias atom THY C2* C2'
alias atom THY C3* C3'
alias atom THY O3* O3'
alias atom GUA O5* O5'
alias atom GUA C5* C5'
alias atom GUA C4* C4'
alias atom GUA O4* O4'
alias atom GUA C1* C1'
alias atom GUA C2* C2'
alias atom GUA C3* C3'
alias atom GUA O3* O3'
alias atom ADE O5* O5'
alias atom ADE C5* C5'
alias atom ADE C4* C4'
alias atom ADE O4* O4'
alias atom ADE C1* C1'
alias atom ADE C2* C2'
alias atom ADE C3* C3'
alias atom ADE O3* O3'
alias atom CYT O5* O5'
alias atom CYT C5* C5'
alias atom CYT C4* C4'
alias atom CYT O4* O4'
alias atom CYT C1* C1'
alias atom CYT C2* C2'
alias atom CYT C3* C3'
alias atom CYT O3* O3'
segment A {
first 5TER
last 3TER
pdb A.pdb
}
patch DEO2 A:2
patch DEO2 A:4
patch DEO2 A:5
patch DEO2 A:6
patch DEO2 A:10
patch DEO2 A:12
patch DEO1 A:1
patch DEO1 A:3
patch DEO1 A:7
patch DEO1 A:8
patch DEO1 A:9
patch DEO1 A:11
coordpdb A.pdb A
segment B {
first 5TER
last 3TER
pdb B.pdb
}
patch DEO2 B:2
patch DEO2 B:4
patch DEO2 B:5
patch DEO2 B:6
patch DEO2 B:10
patch DEO2 B:12
patch DEO1 B:1
patch DEO1 B:3
patch DEO1 B:7
patch DEO1 B:8
patch DEO1 B:9
patch DEO1 B:11
coordpdb B.pdb B
segment SOD {
pdb ions.pdb
}
coordpdb ions.pdb SOD
guesscoord
writepsf psfgen_ions.psf
writepdb psfgen_ions.pdb
END
exit
- Run it with source psfgen_ions.sh, examine log and PDB file.
- Time to hydrate the system : Create a file with the name vmd.script containing the following script (for VMD) :
#
# This is a short script implementing VMD's 'solvate' to prepare
# a fully solvated system for a periodic boundary simulation.
# It also prepares two pdb files needed for implementing restrains
# during the heating-up phase.
#
#
# Make water box
#
solvate psfgen_ions.psf psfgen_ions.pdb -o hydrated -b 1.80 -t 15.0
#
# Here you can add additional ions to emulate higher ionic strength
# conditions. In this case we add 50mM salt, increasing the effective
# ionic strength to approximately 250mM.
#
package require autoionize
autoionize -psf hydrated.psf -pdb hydrated.pdb -is 0.050
#
# Prepare restraints files
#
mol load psf ionized.psf pdb ionized.pdb
set all [atomselect top all]
set sel [atomselect top "nucleic and name P"]
$all set beta 0
$sel set beta 0.5
$all writepdb restrain_P.pdb
set all [atomselect top all]
set to_fix [atomselect top "nucleic and backbone"]
$all set beta 0
$to_fix set beta 1
$all writepdb fix_backbone.pdb
- Run this script via VMD :
- Locate VMD's console (window with the prompt)
- In the console give source vmd.script
- If all goes well you should see your fully hydrated and ionised system on VMD's graphics window.
- To finish type quit in the console.
- Use rasmol or vmd to study your system (ionized.pdb). Make sure that there are no waters or ions accidentally placed inside your molecule's hydrophobic core.
- The last step before running NAMD is to determine the limits (along the orthogonal frame) of the system. A fast method to do this is to use the program pdbset from the CCP4 suite of program. Here it is how :
- Start it : pdbset xyzin ionized.pdb >& pdbset.log
- Edit the file pdbset.log. Somewhere near the end of it you will see something similar to :
Orthogonal Coordinate limits in output file:
Minimum Maximum Centre Range
On X : -37.70 36.29 -0.71 74.00
On Y : -29.96 30.01 0.03 59.97
On Z : -30.39 29.60 -0.39 60.00
- Note these numbers, especially the range (on x,y,z) and position of centre.
- Create a NAMD minimisation and heating-up script with the name heat.namd containing the following :
#
# Input files
#
structure ionized.psf
coordinates ionized.pdb
parameters par_all27_prot_na.inp
paraTypeCharmm on
#
# Output files & writing frequency for DCD
# and restart files
#
outputname output/heat_out
binaryoutput off
restartname output/restart
restartfreq 1000
binaryrestart yes
dcdFile output/heat_out.dcd
dcdFreq 200
#
# Frequencies for logs and the xst file
#
outputEnergies 20
outputTiming 200
xstFreq 200
#
# Timestep & friends
#
timestep 2.0
stepsPerCycle 8
nonBondedFreq 1
fullElectFrequency 2
#
# Simulation space partitioning
#
switching on
switchDist 10
cutoff 12
pairlistdist 13.5
#
# Basic dynamics
#
temperature 0
COMmotion no
dielectric 1.0
exclude scaled1-4
1-4scaling 1.0
rigidbonds all
#
# Particle Mesh Ewald parameters.
#
Pme on
PmeGridsizeX 80 # <===== CHANGE ME
PmeGridsizeY 60 # <===== CHANGE ME
PmeGridsizeZ 60 # <===== CHANGE ME
#
# Periodic boundary things
#
wrapWater on
wrapNearest on
cellBasisVector1 74.00 00.00 00.00 # <===== CHANGE ME
cellBasisVector2 00.00 60.00 00.00 # <===== CHANGE ME
cellBasisVector3 00.00 00.00 60.00 # <===== CHANGE ME
cellOrigin 0.00 0.00 0.00 # <===== CHANGE ME
#
# Fixed atoms for initial heating-up steps
#
fixedAtoms on
fixedAtomsForces on
fixedAtomsFile fix_backbone.pdb
fixedAtomsCol B
#
# Restrained atoms for initial heating-up steps
#
constraints on
consRef restrain_P.pdb
consKFile restrain_P.pdb
consKCol B
#
# Langevin dynamics parameters
#
langevin on
langevinDamping 10
langevinTemp 320 # <===== Check me
langevinHydrogen on
langevinPiston on
langevinPistonTarget 1.01325
langevinPistonPeriod 200
langevinPistonDecay 100
langevinPistonTemp 320 # <===== Check me
useGroupPressure yes
##########################################
# The actual minimisation and heating-up
# protocol follows. The number of steps
# shown below are too small for a real run
##########################################
#
# run one step to get into scripting mode
#
minimize 0
#
# turn off pressure control until later
#
langevinPiston off
#
# minimize nonbackbone atoms
#
minimize 400 ;# <===== CHANGE ME
output output/min_fix
#
# min all atoms
#
fixedAtoms off
minimize 400 ;# <===== CHANGE ME
output output/min_all
#
# heat with Ps restrained
#
set temp 20;
while { $temp < 321 } { ;# <===== Check me
langevinTemp $temp
run 400 ;# <===== CHANGE ME
output output/heat_P
set temp [expr $temp + 20]
}
#
# equilibrate volume with Ps restrained
#
langevinPiston on
run 400 ;# <===== CHANGE ME
output output/equil_P
#
# equilibrate volume without restraints
#
constraintScaling 0
run 2000 ;# <===== CHANGE ME
- You can now give it a quick try with NAMD just to make sure it starts without problems. To avoid overloading machines that are already busy with real calculations you must review the cluster usage as follows :
- Type mosmon from your terminal. You should see something similar to this
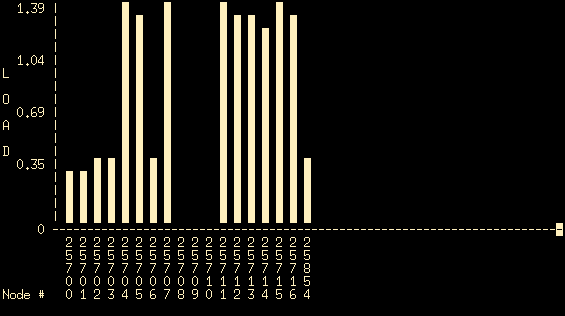
- This graph shows (in real time) the CPU load for each of the nodes that are currently part of the cluster. The horizontal axis shows the various nodes, the vertical axis shows the corresponding load. If all machines are working properly and they are all running the openMosix linux kernel you should see at least 18 nodes (numbered 25700-25716, plus another node with ID 25854). In this case all cluster nodes are running a proper operating system (and can be seen in the mosmon output) and three of these (25708, 25709 and 25710 corresponding to pc08, pc09 and pc10) are idle. So, nodes pc08, pc09 and pc10 are good candidates for performing your tests.
- Type q to stop mosmon and then give qmon (from your terminal). The main Sun Grid Engine GUI window should appear:
- Select "Queue control". This should pop-up the corresponding window :
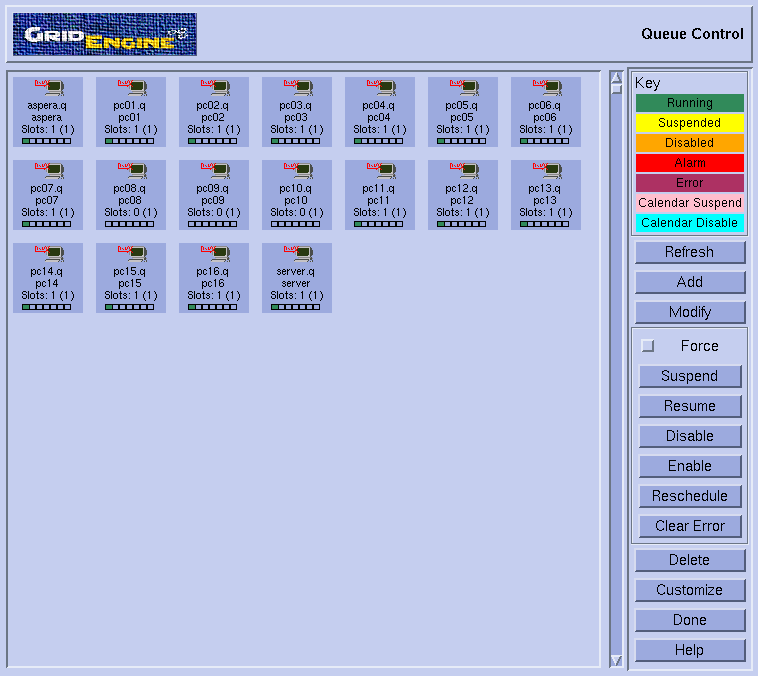
- Note the small green boxes (indicating that a job is running) on all nodes except pc08, pc09 and pc10. So, it does look like we could use these three machines for the tests. Press 'Done' on the queue control window and then exit in the qmon window.
- As a first test lets run NAMD on a single node, e.g. pc09 : login to it with ssh pc9 (use your password to login). Then cd to the directory containing your file : oops, no such file or directory ? That's right : you created the files on your local machine, which probably isn't pc09. So, here comes the need for a cluster-wide filesystem. This is implemented in the form of the /work directory. Proceed as follows :
- Now go back to the directory containing the files you created. Of all the files present in there you only need to copy those few :
cp ionized.p* par_all27_prot_na.inp heat.namd fix_backbone.pdb restrain_P.pdb /work/tmp/my_tests/
- ls and you should see your files (although you are connected to pc9).
- mkdir output will create a subdirectory where the output files from NAMD will be written (during the run).
- Now, go for it : runhome /usr/local/NAMD_2.5/namd2 heat.namd. The runhome command tells the openMosix kernel to run the job on the local machine (not to migrate it away). Once the program performs a couple of minimisation steps stop it with <CTRL-C>. What you should see should be similar to :
Charm++: standalone mode (not using charmrun)
Info: NAMD 2.5 for Linux-i686
Info:
Info: Please visit http://www.ks.uiuc.edu/Research/namd/
Info: and send feedback or bug reports to namd@ks.uiuc.edu
Info:
Info: Please cite Kale et al., J. Comp. Phys. 151:283-312 (1999)
Info: in all publications reporting results obtained with NAMD.
Info:
Info: Based on Charm++/Converse 050612 for net-linux-icc
Info: Built Fri Sep 26 17:33:59 CDT 2003 by jim on lisboa.ks.uiuc.edu
Info: Sending usage information to NAMD developers via UDP. Sent data is:
Info: 1 NAMD 2.5 Linux-i686 1 aspera.cluster.mbg.gr glykos
Info: Running on 1 processors.
Info: 1335 kB of memory in use.
Measuring processor speeds... Done.
Info: Configuration file is heat.namd
TCL: Suspending until startup complete.
Info: SIMULATION PARAMETERS:
Info: TIMESTEP 2
Info: NUMBER OF STEPS 0
Info: STEPS PER CYCLE 8
Info: PERIODIC CELL BASIS 1 74 0 0
Info: PERIODIC CELL BASIS 2 0 60 0
Info: PERIODIC CELL BASIS 3 0 0 60
Info: PERIODIC CELL CENTER 0 0 0
Info: WRAPPING WATERS AROUND PERIODIC BOUNDARIES ON OUTPUT.
Info: WRAPPING TO IMAGE NEAREST TO PERIODIC CELL CENTER.
Info: LOAD BALANCE STRATEGY Other
Info: LDB PERIOD 1600 steps
Info: FIRST LDB TIMESTEP 40
Info: LDB BACKGROUND SCALING 1
Info: HOM BACKGROUND SCALING 1
Info: PME BACKGROUND SCALING 1
Info: MAX SELF PARTITIONS 50
Info: MAX PAIR PARTITIONS 20
Info: SELF PARTITION ATOMS 125
Info: PAIR PARTITION ATOMS 200
Info: PAIR2 PARTITION ATOMS 400
Info: INITIAL TEMPERATURE 0
Info: CENTER OF MASS MOVING? NO
Info: DIELECTRIC 1
Info: EXCLUDE SCALED ONE-FOUR
Info: 1-4 SCALE FACTOR 1
Info: DCD FILENAME output/heat_out.dcd
Info: DCD FREQUENCY 200
Warning: INITIAL COORDINATES WILL NOT BE WRITTEN TO DCD FILE
Info: XST FILENAME output/heat_out.xst
Info: XST FREQUENCY 200
Info: NO VELOCITY DCD OUTPUT
Info: OUTPUT FILENAME output/heat_out
Info: RESTART FILENAME output/restart
Info: RESTART FREQUENCY 1000
Info: BINARY RESTART FILES WILL BE USED
Info: SWITCHING ACTIVE
Info: SWITCHING ON 10
Info: SWITCHING OFF 12
Info: PAIRLIST DISTANCE 13.5
Info: PAIRLIST SHRINK RATE 0.01
Info: PAIRLIST GROW RATE 0.01
Info: PAIRLIST TRIGGER 0.3
Info: PAIRLISTS PER CYCLE 2
Info: PAIRLISTS ENABLED
Info: MARGIN 0.48
Info: HYDROGEN GROUP CUTOFF 2.5
Info: PATCH DIMENSION 16.48
Info: ENERGY OUTPUT STEPS 20
Info: TIMING OUTPUT STEPS 200
Info: FIXED ATOMS ACTIVE
Info: FORCES BETWEEN FIXED ATOMS ARE CALCULATED
Info: HARMONIC CONSTRAINTS ACTIVE
Info: HARMONIC CONS EXP 2
Info: LANGEVIN DYNAMICS ACTIVE
Info: LANGEVIN TEMPERATURE 320
Info: LANGEVIN DAMPING COEFFICIENT IS 10 INVERSE PS
Info: LANGEVIN DYNAMICS APPLIED TO HYDROGENS
Info: LANGEVIN PISTON PRESSURE CONTROL ACTIVE
Info: TARGET PRESSURE IS 1.01325 BAR
Info: OSCILLATION PERIOD IS 200 FS
Info: DECAY TIME IS 100 FS
Info: PISTON TEMPERATURE IS 320 K
Info: PRESSURE CONTROL IS GROUP-BASED
Info: INITIAL STRAIN RATE IS 0 0 0
Info: CELL FLUCTUATION IS ISOTROPIC
Info: PARTICLE MESH EWALD (PME) ACTIVE
Info: PME TOLERANCE 1e-06
Info: PME EWALD COEFFICIENT 0.257952
Info: PME INTERPOLATION ORDER 4
Info: PME GRID DIMENSIONS 80 60 60
Info: Attempting to read FFTW data from FFTW_NAMD_2.5_Linux-i686.txt
Info: Optimizing 6 FFT steps. 1... 2... 3... 4... 5... 6... Done.
Info: Writing FFTW data to FFTW_NAMD_2.5_Linux-i686.txt
Info: FULL ELECTROSTATIC EVALUATION FREQUENCY 4
Info: USING VERLET I (r-RESPA) MTS SCHEME.
Info: C1 SPLITTING OF LONG RANGE ELECTROSTATICS
Info: PLACING ATOMS IN PATCHES BY HYDROGEN GROUPS
Info: RIGID BONDS TO HYDROGEN : ALL
Info: ERROR TOLERANCE : 1e-08
Info: MAX ITERATIONS : 100
Info: RIGID WATER USING SETTLE ALGORITHM
Info: NONBONDED FORCES EVALUATED EVERY 2 STEPS
Info: RANDOM NUMBER SEED 1109584307
Info: USE HYDROGEN BONDS? NO
Info: COORDINATE PDB ionized.pdb
Info: STRUCTURE FILE ionized.psf
Info: PARAMETER file: CHARMM format!
Info: PARAMETERS par_all27_prot_na.inp
Info: SUMMARY OF PARAMETERS:
Info: 250 BONDS
Info: 622 ANGLES
Info: 1049 DIHEDRAL
Info: 73 IMPROPER
Info: 130 VDW
Info: 0 VDW_PAIRS
Info: ****************************
Info: STRUCTURE SUMMARY:
Info: 25117 ATOMS
Info: 17038 BONDS
Info: 9599 ANGLES
Info: 2228 DIHEDRALS
Info: 68 IMPROPERS
Info: 0 EXCLUSIONS
Info: 22 CONSTRAINTS
Info: 176 FIXED ATOMS
Info: 24569 RIGID BONDS
Info: 0 RIGID BONDS BETWEEN FIXED ATOMS
Info: 50254 DEGREES OF FREEDOM
Info: 8647 HYDROGEN GROUPS
Info: 108 HYDROGEN GROUPS WITH ALL ATOMS FIXED
Info: TOTAL MASS = 154535 amu
Info: TOTAL CHARGE = 8.23289e-07 e
Info: *****************************
Info: Entering startup phase 0 with 7301 kB of memory in use.
Info: Entering startup phase 1 with 7301 kB of memory in use.
Info: Entering startup phase 2 with 8984 kB of memory in use.
Info: Entering startup phase 3 with 9184 kB of memory in use.
Info: PATCH GRID IS 4 (PERIODIC) BY 3 (PERIODIC) BY 3 (PERIODIC)
Info: REMOVING COM VELOCITY 0 0 0
Info: LARGEST PATCH (5) HAS 760 ATOMS
Info: Entering startup phase 4 with 12394 kB of memory in use.
Info: PME using 1 and 1 processors for FFT and reciprocal sum.
Creating Strategy 4
Creating Strategy 4
Info: PME GRID LOCATIONS: 0
Info: PME TRANS LOCATIONS: 0
Info: Optimizing 4 FFT steps. 1... 2... 3... 4... Done.
Info: Entering startup phase 5 with 13567 kB of memory in use.
Info: Entering startup phase 6 with 13567 kB of memory in use.
Info: Entering startup phase 7 with 13567 kB of memory in use.
Info: COULOMB TABLE R-SQUARED SPACING: 0.0625
Info: COULOMB TABLE SIZE: 769 POINTS
Info: NONZERO IMPRECISION IN COULOMB TABLE: 2.64698e-22 (712) 2.64698e-22 (712)
Info: NONZERO IMPRECISION IN COULOMB TABLE: 1.26218e-29 (742) 1.57772e-29 (742)
Info: NONZERO IMPRECISION IN COULOMB TABLE: 1.27055e-21 (767) 1.48231e-21 (767)
Info: Entering startup phase 8 with 16909 kB of memory in use.
Info: Finished startup with 21797 kB of memory in use.
TCL: Minimizing for 0 steps
ETITLE: TS BOND ANGLE DIHED IMPRP ELECT VDW BOUNDARY MISC KINETIC TOTAL TEMP TOTAL2 TOTAL3 TEMPAVG PRESSURE GPRESSURE VOLUME PRESSAVG GPRESSAVG
ENERGY: 0 8367.1615 2562.3243 745.3077 0.7495 -86828.1909 2661304.0749 0.0000 0.0000 0.0000 2586151.4269 0.0000 2586151.4269 2586151.4269 0.0000 2770784.8777 2821435.1130 266400.0000 2770784.8777 2821435.1130
TCL: Setting parameter langevinPiston to off
TCL: Minimizing for 400 steps
ETITLE: TS BOND ANGLE DIHED IMPRP ELECT VDW BOUNDARY MISC KINETIC TOTAL TEMP TOTAL2 TOTAL3 TEMPAVG PRESSURE GPRESSURE VOLUME PRESSAVG GPRESSAVG
ENERGY: 0 8367.1615 2562.3243 745.3077 0.7495 -86828.1909 2661304.0749 0.0000 0.0000 0.0000 2586151.4269 0.0000 2586151.4269 2586151.4269 0.0000 2770784.8777 2821435.1130 266400.0000 2770784.8777 2821435.1130
INITIAL STEP: 1e-06
GRADIENT TOLERANCE: 6.07456e+07
ENERGY: 1 8461.3964 2575.7790 745.3495 0.7474 -86744.8887 66834.9357 0.0000 0.0000 0.0000 -8126.6806 0.0000 -8126.6806 -8126.6806 0.0000 62244.7987 65640.3834 266400.0000 62244.7987 65640.3834
ENERGY: 2 8797.5006 2631.6879 745.3945 0.7454 -86710.0767 39177.7886 0.0000 0.0000 0.0000 -35356.9597 0.0000 -35356.9597 -35356.9597 0.0000 33177.5662 35521.3466 266400.0000 33177.5662 35521.3466
ENERGY: 3 10026.8780 2749.8692 745.4941 0.7418 -86681.3159 31642.7422 0.0000 0.0000 0.0000 -41515.5906 0.0000 -41515.5906 -41515.5906 0.0000 24842.4717 28926.6604 266400.0000 24842.4717 28926.6604
ENERGY: 4 16301.5980 3252.9024 745.7321 0.7358 -86621.8424 6474574.1627 0.0000 0.0000 0.0000 6408253.2887 0.0000 6408253.2887 6408253.2887 0.0000 6747235.8916 6748522.4575 266400.0000 6747235.8916 6748522.4575
BRACKET: 6e-06 6.44977e+06 -8.35686e+09 2.51346e+09 1.63163e+09
- Wouldn't it be great to run NAMD a bit faster ? Say, approximately three times faster ? Isn't it a pity to have pc08 and pc10 filtering the dust in the terminal room ? While you are at /work/tmp/my_tests/ create a file with the name NAMD.sh containing the following :
#!/bin/csh -f
#
#
# The name of the job
#
#$ -N My_test
#
# ====> CHANGE ME <====
#
# The parallel environment (mpi_fast) and number of processors (3)
# The options are : mpi_fast : the 9 new machines
# mpi_slow : the 9 older machines
# mpich : all machines on the cluster
#
#$ -pe mpi_fast 3
#
# The version of MPICH to use, transport protocol & a trick to delete cleanly
# running MPICH jobs ...
#
#$ -v MPIR_HOME=/usr/local/mpich-ssh
#$ -v P4_RSHCOMMAND=rsh
#$ -v MPICH_PROCESS_GROUP=no
#$ -v CONV_RSH=rsh
#
# Nodes that can server as master queues
#
#$ -masterq pc01.q,pc02.q,pc03.q,pc04.q,pc05.q,pc06.q,pc07.q,pc08.q,pc09.q,pc10.q,pc11.q,pc12.q,pc13.q,pc14.q,pc16.q
#
# Execute from the current working directory ...
#
#$ -cwd
#
# Standard error and output should go into the current working directory ...
#
#$ -e ./
#$ -o ./
#
# Built nodelist file for charmrun
#
echo "Got $NSLOTS slots."
echo "group main" > $TMPDIR/charmlist
awk '{print "host " $1}' $TMPDIR/machines >> $TMPDIR/charmlist
cat $TMPDIR/charmlist
#
# ====> CHANGE ME <====
#
# The name of the NAMD script file is defined here (heat.namd) as well as
# the name of the job's log file (LOG)
#
/usr/local/NAMD_2.5/charmrun /bin/runhome /usr/local/NAMD_2.5/namd2 ++nodelist $TMPDIR/charmlist +p $NSLOTS heat.namd > LOG
- This script is a parallel NAMD job submission script for the Sun Grid Engine. All you have to do is : qsub NAMD.sh (from the /work/tmp/my_tests/ directory). You should see a message containing your job's ID.
- Type qstat : you should see your job and its status changing from qw to t to r.
- Use mosmon to confirm that the previously idle machines are indeed doing something useful.
- Use qmon to review cluster usage, and to see your job in Job Control/Running Jobs.
- tail -f LOG should show you the growing log file from your job.
- Type mknamdplot LOG and then click Draw to see a collection of graphs showing the evolution of quantities like the system's total energy, pressure, temperature, bond and angle energies, … :
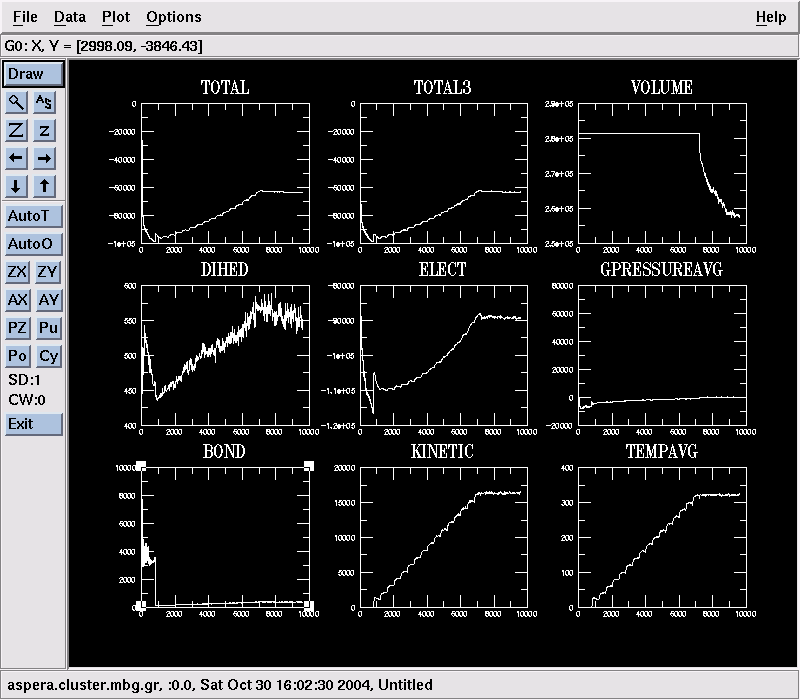
- The heating-up NAMD job will take 2-3 hours to finish. Let it do so. But if you'd rather not : qdel JobID will kill your job (or you can use the qmon GUI).
- When the job is done review the files that have been created in /work/tmp/my_tests/output/. You should see something like
-rw-rw-r-- 1 glykos glykos 2029503 Oct 30 15:19 equil_P.coor
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 15:19 equil_P.vel
-rw-rw-r-- 1 glykos glykos 222 Oct 30 15:19 equil_P.xsc
-rw-rw-r-- 1 glykos glykos 2029503 Oct 30 15:16 heat_P.coor
-rw-rw-r-- 1 glykos glykos 2029503 Oct 30 15:13 heat_P.coor.BAK
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 15:16 heat_P.vel
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 15:13 heat_P.vel.BAK
-rw-rw-r-- 1 glykos glykos 153 Oct 30 15:16 heat_P.xsc
-rw-rw-r-- 1 glykos glykos 153 Oct 30 15:13 heat_P.xsc.BAK
-rw-rw-r-- 1 glykos glykos 2029503 Oct 30 15:36 heat_out.coor
-rw-r--r-- 1 glykos glykos 14613396 Oct 30 15:36 heat_out.dcd
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 15:36 heat_out.vel
-rw-rw-r-- 1 glykos glykos 227 Oct 30 15:36 heat_out.xsc
-rw-rw-r-- 1 glykos glykos 3364 Oct 30 15:36 heat_out.xst
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 14:25 min_all.coor
-rw-rw-r-- 1 glykos glykos 2029501 Oct 30 14:25 min_all.vel
-rw-rw-r-- 1 glykos glykos 152 Oct 30 14:25 min_all.xsc
-rw-rw-r-- 1 glykos glykos 2029502 Oct 30 14:19 min_fix.coor
-rw-rw-r-- 1 glykos glykos 2029501 Oct 30 14:19 min_fix.vel
-rw-rw-r-- 1 glykos glykos 152 Oct 30 14:19 min_fix.xsc
-rw-rw-r-- 1 glykos glykos 608836 Oct 30 15:31 restart.coor
-rw-rw-r-- 1 glykos glykos 608836 Oct 30 15:22 restart.coor.old
-rw-rw-r-- 1 glykos glykos 608836 Oct 30 15:31 restart.vel
-rw-rw-r-- 1 glykos glykos 608836 Oct 30 15:22 restart.vel.old
-rw-rw-r-- 1 glykos glykos 229 Oct 30 15:31 restart.xsc
-rw-rw-r-- 1 glykos glykos 228 Oct 30 15:22 restart.xsc.old
- Play time : from the output/ directory give vmd ../ionized.psf heat_out.dcd
- You can now start preparing the equilibration-production run :
- cp heat_out.coor heat_out.vel heat_out.xsc ../../equi/
- cp ionized.p* par_all27_prot_na.inp ../equi/
- Create a NAMD equilibration script with the name equi.namd containing the following :
#
# Input files
#
structure ionized.psf
coordinates heat_out.coor
velocities heat_out.vel
extendedSystem heat_out.xsc
parameters par_all27_prot_na.inp
paraTypeCharmm on
#
# Output files & writing frequency for DCD
# and restart files
#
outputname output/equi_out
binaryoutput off
restartname output/restart
restartfreq 1000
binaryrestart yes
dcdFile output/equi_out.dcd
dcdFreq 200
#
# Frequencies for logs and the xst file
#
outputEnergies 20
outputTiming 200
xstFreq 200
#
# Timestep & friends
#
timestep 2.0
stepsPerCycle 8
nonBondedFreq 1
fullElectFrequency 2
#
# Simulation space partitioning
#
switching on
switchDist 10
cutoff 12
pairlistdist 13.5
#
# Basic dynamics
#
COMmotion no
dielectric 1.0
exclude scaled1-4
1-4scaling 1.0
rigidbonds all
#
# Particle Mesh Ewald parameters.
#
Pme on
PmeGridsizeX 80 # <===== CHANGE ME
PmeGridsizeY 60 # <===== CHANGE ME
PmeGridsizeZ 60 # <===== CHANGE ME
#
# Periodic boundary things
#
wrapWater on
wrapNearest on
wrapAll on
#
# Langevin dynamics parameters
#
langevin on
langevinDamping 1
langevinTemp 320 # <===== Check me
langevinHydrogen on
langevinPiston on
langevinPistonTarget 1.01325
langevinPistonPeriod 200
langevinPistonDecay 100
langevinPistonTemp 320 # <===== Check me
useGroupPressure yes
firsttimestep 9600 # <===== CHANGE ME
run 4000 ;# <===== CHANGE ME
- Prepare a submission script for SGE, say NAMD.sh :
#!/bin/csh -f
#
#
# The name of the job
#
#$ -N test_equi
#
# The parallel environment (mpi_fast) and number of processors (9) ...
#
#$ -pe mpi_fast 3
#
# The version of MPICH to use, transport protocol & a trick to delete cleanly
# running MPICH jobs ...
#
#$ -v MPIR_HOME=/usr/local/mpich-ssh
#$ -v P4_RSHCOMMAND=rsh
#$ -v MPICH_PROCESS_GROUP=no
#$ -v CONV_RSH=rsh
#
# Nodes that can server as master queues
#
#$ -masterq pc01.q,pc02.q,pc03.q,pc04.q,pc05.q,pc06.q,pc07.q,pc08.q,pc09.q,pc10.q,pc11.q,pc12.q,pc13.q,pc14.q,pc16.q
#
# Execute from the current working directory ...
#
#$ -cwd
#
# Standard error and output should go into the current working directory ...
#
#$ -e ./
#$ -o ./
#
# Built nodelist file for charmrun
#
echo "Got $NSLOTS slots."
echo "group main" > $TMPDIR/charmlist
awk '{print "host " $1}' $TMPDIR/machines >> $TMPDIR/charmlist
cat $TMPDIR/charmlist
#
# Ready ...
#
/usr/local/NAMD_2.5/charmrun /bin/runhome /usr/local/NAMD_2.5/namd2 ++nodelist $TMPDIR/charmlist +p $NSLOTS equi.namd > LOG
![[Home]](/wiki.png)