Difference (from prior major revision)
Added: 0a1,2
> Beware: incomplete work in progress ...
> == Prelude ==
Changed: 2,3c4,40
< * The linux kernel is OpenMosix. This not only allows transparent process migration between the nodes, but it also offers a cluster-wide common filesystem. Unfortunately, process migration is not always a nice thing to have (the overhead associated with continuously moving a job around the nodes makes migration a bad idea for long jobs, see below for the commands needed to disallow job migration).
< * The availability of a proper (cluster-wide) queuing system (the Sun Grid Engine) supporting parallel (MPI-based) program execution. This is a nice system to have for large parallel jobs, but is probably too complex if you just want to run a simple stand-alone job.
to
> * The linux kernel is openmosix. This not only allows transparent process migration between the nodes, but it also offers a cluster-wide common filesystem. Unfortunately, process migration is not always a nice thing to have (the overhead associated with continuously moving a job around the nodes makes migration a bad idea for long jobs, see below for the commands needed to disallow job migration).
> * The availability of a proper (cluster-wide) queuing system (the Sun Grid Engine, SGE) supporting parallel (MPI-based) program execution. This is a nice system to have for large parallel jobs, but is probably too complex if you just want to run a simple stand-alone job. Simpler procedures are mentioned later on.
> == LAN and Accessibility ==
> The cluster uses an isolated LAN with IPs ranging from 190.100.100.100 to 190.100.100.XXX. DNS for the LAN is offered by the head node which is the 190.100.100.100 machine (server.cluster.mbg.gr). The other nodes are pc01.cluster.mbg.gr, ..., with aliases pc1, pc2, ... The head-node also serves as a http-proxy-server (running <tt>squid</tt>) allowing the other nodes to access the network (/only/ http allowed).
> The head-node (server from now on) has two network interfaces. One is the internal (cluster) interface. The second interface connects the server (and the server only) to the outside world. The address of this second interface is dynamic of the form dhcp-XXX.mbg.duth.gr. The DHCPD-based interface is firewalled with respect to foreign addresses, *with the following exceptions:*
> * The http and ntp ports are open. The implication is that if you know the address of the second interface, you can see what the cluster is doing from home by going to something like http://dhcp-142.mbg.duth.gr/
> * For addresses of the type dhcp-XXX.mbg.duth.gr (193.92.240.XXX) the server allows connections on the ssh port (with X11 forwarding enabled). The implication is that if you are sitting in front of a box that can open a secure shell connection, and if that box has an MBG address, then you should be able to connect to the server from your office (and assuming that you have an account) by saying something like <tt>ssh dhcp-142.mbg.duth.gr</tt>
> == Filesystem things ==
> Each node (plus the server, of course) has its local (ext3 formatted) disk, complete with a full copy of the operating system plus programs (mostly in /usr/local). To be able to run parallel jobs, a common filesystem is needed and this is offered by openmosix's MFS (mosix filesystem). The mount point for the cluster-wide filesystem is <tt>/work</tt>. To make this clear: commands like <tt>cd /home/myself</tt> or <tt>cd /usr/local/bin</tt> will take you to the corresponding directory on the *local* filesystem of the node that you are currently logged-in. On the other hand, all files and directories that reside inside <tt>/work</tt> are visible from all nodes. Now the crucial question: what is the physical location of <tt>/work</tt> ? (in other words, where is the /work stuff get written to?). The answer is that <tt>/work</tt> is physically mounted on the server's <tt>/tmp</tt> directory. To make this clear: <tt>/work</tt> is a handle pointing to the server's <tt>/tmp</tt> directory. If you are logged to the server, then doing an <tt>ls</tt> in
> <tt>/work</tt> and in <tt>/tmp</tt> will show you the same files. But if you are logged to, say, pc08, the command <tt>cd /tmp ; ls</tt> will show you the contents of the *local* (pc8's) /tmp directory.
> Based on the discussion above, you could in principle do a
> <code>
> cd /work
> mkdir mystuff
> cd mystuff
> cp /home/myself/myprogram ./
> ./myprogram < input > output
> </code>
> and run your programs (even the stand-alone) from the common filesystem. This is not a good idea for two reasons: The first is that all input and output ...
> == Approaching the cluster ==
> After logging-in to the server, or (physically) to one of the cluster's nodes, open a unix shell and type <tt>mosmon</tt>. You should get a graphical view of how many machines are alive and whether they are busy or otherwise. If, for example, you see something like
> [[image: mosmon output example]]
> then you will know things are quite busy. Things to note :
> ** The node numbering scheme used by openmosix is quite esoteric. 25700 is the server, 25701 is pc01, ...
> ** Notice that node pc10 (25710) is alive but idle. The reason is that pc10 is used by students in windoze mode and may be rebooted unexpectedly.
> ** The higher load of nodes pc04, pc05, pc07 and pc11-pc16 is artificial. These nodes are the old (733 MHz) machines and openmosix assumes that the same load on a weaker machine is effectively a higher load.
> Given the number of nodes used in this example (17), this is probably a parallel job submitted /via/ SGE. You can check this out by typing 'q' (to quit mosmon) and then <tt>qstat</tt>. If you prefer GUIs, give 'qmon' and then click 'Job control' followed by 'Running Jobs'. Exit with 'Done' and then 'Exit'.
> == Being nice ==
> Parallel jobs are rather sensitive to disturbances of any of the participating nodes. For this reason, when the cluster is busy running a parallel job it is important to treat the machines gently:
> * When you login physically to the server or the nodes, please select a polite (meaning light) window manager like windowmaker. Running KDE (especially on the old nodes) will be a killer for any running jobs.
> * All jobs submitted /via/ SGE are automatically re-niced to the lowest possible priority. The implication is that if you start a normal-priority job on any of the nodes that are already being used for a parallel MPI job, then the whole parallel job (all nodes) will come to a halt (not a nice thing to do). See below for a list of re-niced job-submitting procedures :-)
> == The real thing : submitting a job ==
> For the discussion that follows I will assume that your program is properly installed and running (from the command line). To simplify the discussion that follows I will categorise the problem in program-specific types:
> -----
> === An interactive single-processor job ===
> From the mosmon output identify a node that is alive but idle. Copy your files to
> -----
Beware: incomplete work in progress …
Prelude
The basic differences from a simple bunch of networked PCs are :
- The linux kernel is openmosix. This not only allows transparent process migration between the nodes, but it also offers a cluster-wide common filesystem. Unfortunately, process migration is not always a nice thing to have (the overhead associated with continuously moving a job around the nodes makes migration a bad idea for long jobs, see below for the commands needed to disallow job migration).
- The availability of a proper (cluster-wide) queuing system (the Sun Grid Engine, SGE) supporting parallel (MPI-based) program execution. This is a nice system to have for large parallel jobs, but is probably too complex if you just want to run a simple stand-alone job. Simpler procedures are mentioned later on.
LAN and Accessibility
The cluster uses an isolated LAN with IPs ranging from 190.100.100.100 to 190.100.100.XXX. DNS for the LAN is offered by the head node which is the 190.100.100.100 machine (server.cluster.mbg.gr). The other nodes are pc01.cluster.mbg.gr, …, with aliases pc1, pc2, … The head-node also serves as a http-proxy-server (running squid) allowing the other nodes to access the network (only http allowed).
The head-node (server from now on) has two network interfaces. One is the internal (cluster) interface. The second interface connects the server (and the server only) to the outside world. The address of this second interface is dynamic of the form dhcp-XXX.mbg.duth.gr. The DHCPD-based interface is firewalled with respect to foreign addresses, with the following exceptions:
- The http and ntp ports are open. The implication is that if you know the address of the second interface, you can see what the cluster is doing from home by going to something like http://dhcp-142.mbg.duth.gr/
- For addresses of the type dhcp-XXX.mbg.duth.gr (193.92.240.XXX) the server allows connections on the ssh port (with X11 forwarding enabled). The implication is that if you are sitting in front of a box that can open a secure shell connection, and if that box has an MBG address, then you should be able to connect to the server from your office (and assuming that you have an account) by saying something like ssh dhcp-142.mbg.duth.gr
Filesystem things
Each node (plus the server, of course) has its local (ext3 formatted) disk, complete with a full copy of the operating system plus programs (mostly in /usr/local). To be able to run parallel jobs, a common filesystem is needed and this is offered by openmosix's MFS (mosix filesystem). The mount point for the cluster-wide filesystem is /work. To make this clear: commands like cd /home/myself or cd /usr/local/bin will take you to the corresponding directory on the local filesystem of the node that you are currently logged-in. On the other hand, all files and directories that reside inside /work are visible from all nodes. Now the crucial question: what is the physical location of /work ? (in other words, where is the /work stuff get written to?). The answer is that /work is physically mounted on the server's /tmp directory. To make this clear: /work is a handle pointing to the server's /tmp directory. If you are logged to the server, then doing an ls in /work and in /tmp will show you the same files. But if you are logged to, say, pc08, the command cd /tmp ; ls will show you the contents of the local (pc8's) /tmp directory.
Based on the discussion above, you could in principle do a
cd /work
mkdir mystuff
cd mystuff
cp /home/myself/myprogram ./
./myprogram < input > output
and run your programs (even the stand-alone) from the common filesystem. This is not a good idea for two reasons: The first is that all input and output …
Approaching the cluster
After logging-in to the server, or (physically) to one of the cluster's nodes, open a unix shell and type mosmon. You should get a graphical view of how many machines are alive and whether they are busy or otherwise. If, for example, you see something like
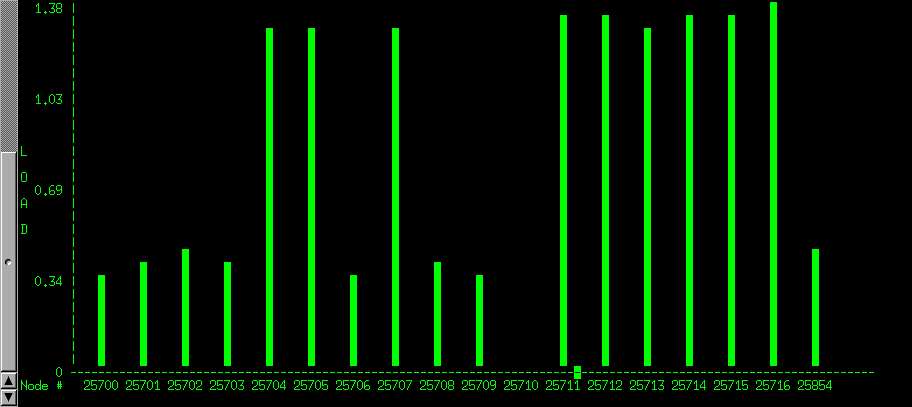
then you will know things are quite busy. Things to note :
- The node numbering scheme used by openmosix is quite esoteric. 25700 is the server, 25701 is pc01, …
- Notice that node pc10 (25710) is alive but idle. The reason is that pc10 is used by students in windoze mode and may be rebooted unexpectedly.
- The higher load of nodes pc04, pc05, pc07 and pc11-pc16 is artificial. These nodes are the old (733 MHz) machines and openmosix assumes that the same load on a weaker machine is effectively a higher load.
Given the number of nodes used in this example (17), this is probably a parallel job submitted via SGE. You can check this out by typing 'q' (to quit mosmon) and then qstat. If you prefer GUIs, give 'qmon' and then click 'Job control' followed by 'Running Jobs'. Exit with 'Done' and then 'Exit'.
Being nice
Parallel jobs are rather sensitive to disturbances of any of the participating nodes. For this reason, when the cluster is busy running a parallel job it is important to treat the machines gently:
- When you login physically to the server or the nodes, please select a polite (meaning light) window manager like windowmaker. Running KDE (especially on the old nodes) will be a killer for any running jobs.
- All jobs submitted via SGE are automatically re-niced to the lowest possible priority. The implication is that if you start a normal-priority job on any of the nodes that are already being used for a parallel MPI job, then the whole parallel job (all nodes) will come to a halt (not a nice thing to do). See below for a list of re-niced job-submitting procedures :-)
The real thing : submitting a job
For the discussion that follows I will assume that your program is properly installed and running (from the command line). To simplify the discussion that follows I will categorise the problem in program-specific types:
An interactive single-processor job
From the mosmon output identify a node that is alive but idle. Copy your files to
![[Home]](/wiki.png)